
Text-based mutual fund strategy similarity
Published:
This databank contains a fund-year level “review” similarity ratio either on a cross-sectional level or a time-series level. I borrow the idea from Hoberg and Phillips (2010, 2016) and Cohen et al. (2020) for their insightful research.
I crawl down all the mutual fund annual reports from EastMoney.com and complement the missing files from CNInfo.com. I extract the discussion and prospectus section as raw corpora and calculate either the cross-sectional or the time-series similarity score. The calculation method is based on the cosine similarity.
For the cross-sectional similarity score, I compute the textual similarity of fund A and fund B that belong to the same investment category in year t. Then, I calculate the average similarity for the focal fund by taking the average value of its similarity score with other funds. This measure is a simple adaptation of the famous Hoberg and Philips’s business similarity (2010, 2016) but in the context of the Chinese mutual fund market. Interestingly, this is a quite unique setting, which is totally different from the fund prospectus (Notable research by Simona Abis) or shareholder letters (Alexander Hillert pioneered this one).
You can download the CS data here.
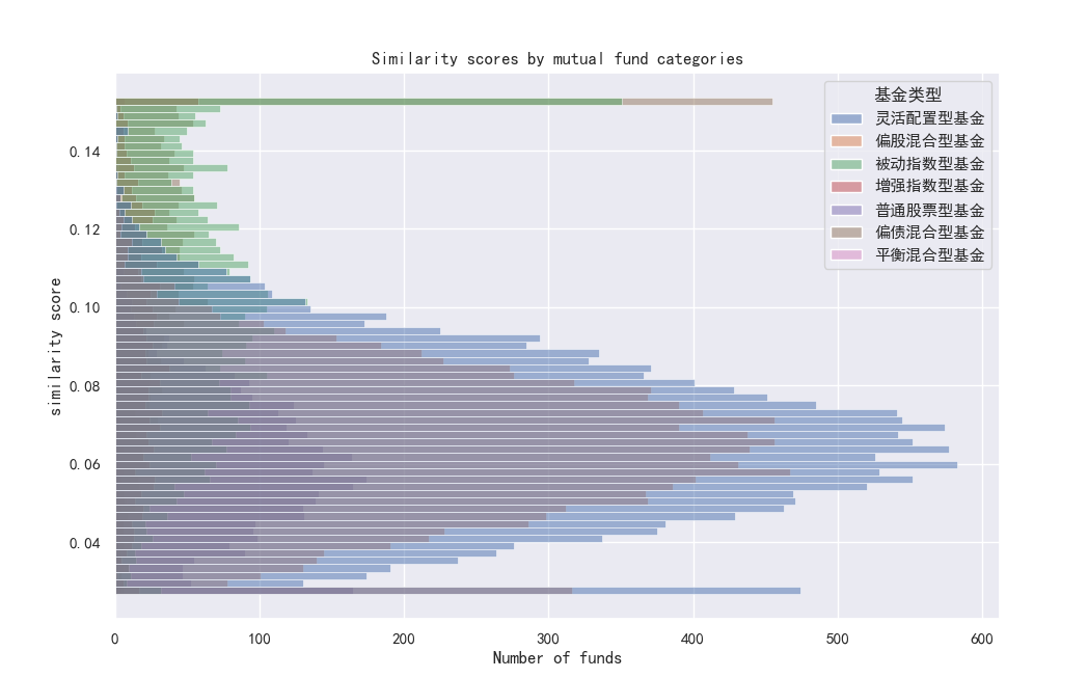
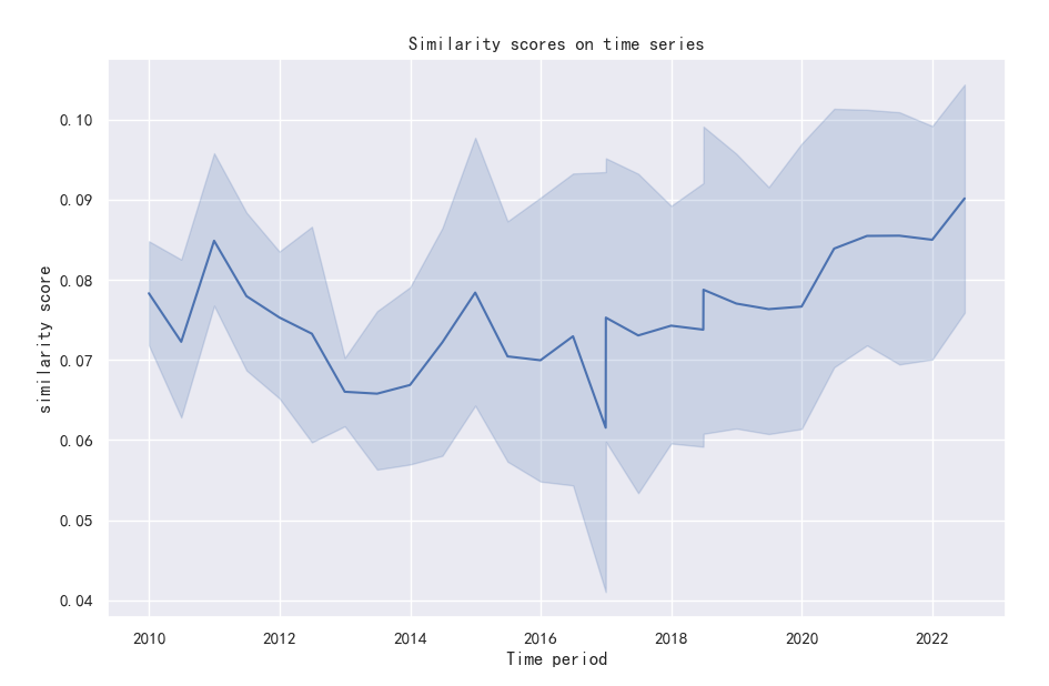
For the time-series similarity score, I follow the work by the Lazy Prices (JF, 2020) by calculating the cosine similarity of fund reports of quarter t and t-1.
You can download the TS data here.
Feel free to use it and please share your good news with me.